
工作站才是端侧大模型的“快乐老家”
难道端侧大模型只和手机相关吗?
你在Mac上召唤过Siri吗?我反正一次也没有过。
这个被称为AI界“老前辈”的虚拟助理,在iPhone上的人气就不温不火,Mac上更是毫无存在感。然而ChatGPT出现后,它在手机上仅有的一点存在感也被进一步拉低了。
眼看就要到11月,ChatGPT上线一周年的日子也不远了。这一年我们见识了生成式人工智能惊人的迭代速度,也让大模型几乎贯穿了这一整年的热门话题。从一开始如何用ChatGPT到“百模大战”,再到行业大模型,如今终于讨论到端侧大模型,可主角却是手机?甚至还有人为此感叹:“2024年将是端侧大模型元年”……
等等!难道“端侧大模型”只包括手机吗?
大家恐怕早就忘了,工作站作为一种专业的高性能终端设备,在更早的时候就已经承载了大模型的应用。当前的工作站已经可以胜任部分对算力要求不是很高的轻度训练工作,所以来说,运行更不会是什么问题。

当然,包括工作站在内,任何桌面设备都拥有一个强大的互联网入口——网页浏览器,你可以用它访问各种在线大模型服务,但是和本地部署大模型相比,在线服务还是有太多限制:
生成数量,很多在线服务需要消耗大量的算力资源,同时也需要依靠收入来维持运营,所以通常会对免费用户采取各种限制措施。例如免费版ChatGPT只能使用GPT 3.5生成的内容,而且限制速度。如果使用工作站本地部署,只需要消耗本地算力资源,当然也无需进一步的额外付费。
自由度,在线服务需要考虑到所在云服务的技术、条款、各地法规限制,有时用户生成内容可能被提醒违规,有的付费服务也会遇到生成速度缓慢、卡顿、生成失败等问题,用户能做的也只有刷新页面、重新输入指令。使用工作站本地部署的大模型,可以尽情发挥想象,会影响体验的因素通常只有硬件配置了。
生成时间,在线服务需要经由广域网传输指令和生成内容,不仅受云服务的性能影响,网络访问速度也是影响生成速度的另一个关键因素,如果是免费用户,或是服务使用人数过多时,可能还需要排队。使用工作站本地部署则不需要考虑这些问题,如果指令包含一些敏感信息,在本地操作也是更安全的方式。
本地部署大模型有这么多好处,所以一些略懂技术知识的专业工作者也已经尝试在自己的工作站上部署大模型了。目前可以在工作站上部署的大模型已经有很多,Stable Diffusion和Llama 2就是最知名的两个。
在文生图领域,Stable Diffusion的名字很响亮,母公司Stability AI还陆续开源了Stable DiffusionV1、StableLM、Stable Diffusion XL等模型,更让它在文生图领域站稳脚跟。
对于个人用户来说,在工作站上部署和使用Stable Diffusion略有门槛,而且你的设备必须使用NVIDIA显卡,至少需要GT1060,显存在4G以上,设备的内存要在16G或以上,运行Windows 10或Windows 11系统,安装只需要执行以下三步:
配置环境,你需要创建Python环境,在基于此创建Stable Diffusion的用户界面,安装cuda等等操作;
配置Stable Diffusion,你需要下载源码,克隆Stable Diffusion WebUI项目,下载Stable Diffusion训练模型;
执行Stable Diffusion,通过运行Stable Diffusion WebUI就能开始你的AI绘图之旅啦!
Stable Diffusion在图像生成领域大显身手的同时,Stability AI并没有闲下来,甚至开始涉足聊天机器人领域。今年8月,Stability AI推出一款名为“Stable Chat”的聊天机器人,功能类似OpenAI的ChatGPT,不过它采用的大语言模型Stable Beluga则是以两代Llama为基础开发的。
Llama是Meta推出的大语言模型,可以理解和生成各种领域的自然语言文本,由于是一款开源产品,Llama 2也被魔改成了各种版本的大语言模型。和Stable Diffusion一样,你也可以把它部署在工作站上使用。
运行Llama 2同样需要使用NVIDIA显卡,最常见的是使用GeForce RTX 3090,拥有24GB内存,可以运行4位量化的LLaMA 30B模型,每秒大约处理4到10个令牌。在Windows系统安装需要执行下面这些步骤:
下载模型,你需要先在Meta官网填写资料并获取密钥,然后在LLaMA的GitHub库来克隆项目库,运行download.sh脚本,输入密钥之后才能获取模型的文件;
转换模型,使用text-generation-webui方式部署,但由于格式不同,则需要先进行转换;
搭建text-generation-webui,在Github克隆text-generation-webui的项目,将huggingface格式文件放入models中,命名一下文件夹,就完成部署了。
这时候你需要通过命令行执行text-generation-webui来与Llama2模型对话,也可以进一步利用text-generation-webui的API,使Llama 2能够在YourChat客户端上执行。
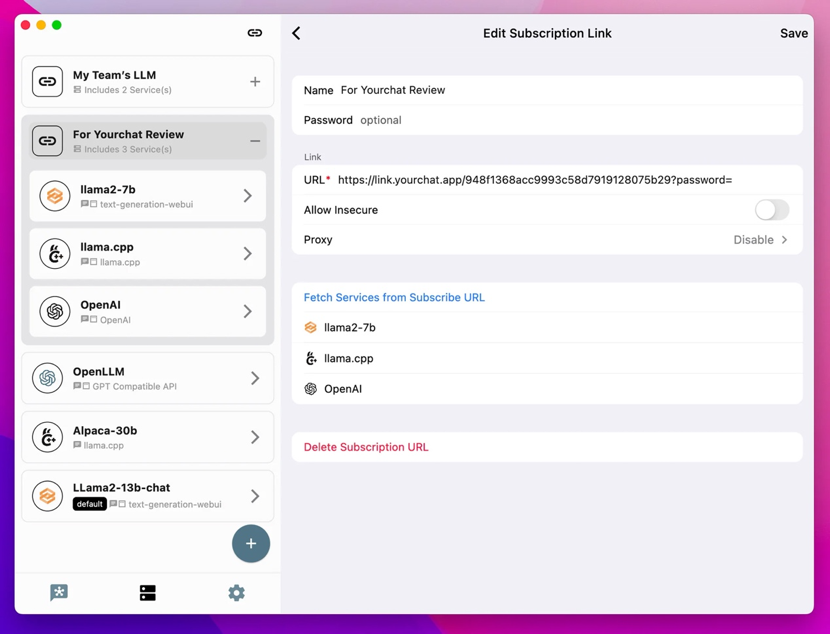
本地部署Llama 2相当于在你的设备里安装了一个反应迅速,并且可以畅所欲言的聊天机器人。的确,你也可以在Mac上和Siri畅所欲言,只是它未必能给你很好的回应。
不过,要只是把它与Siri这样的虚拟助理做对比,就太屈才了!Mac上的Siri几乎没什么存在感,手机上的也没强多少。你有没有发现苹果这两年都没怎么提Siri了?其实在ChatGPT出现后,就已经有传闻称苹果正在给Siri憋个大招,这个“大招”就是端侧大模型。
虽然很多手机厂商都在探索端侧大模型,但至少从现阶段来看,在专业领域的应用上,手机端侧大模型还难以复制工作站上的体验,毕竟两者之间的算力和价格都相差太过悬殊。
工作站价格不菲,使用工作站部署的大模型,能做到的也远不止于简单的对话,它还可以用于灾难响应、交通管理、医疗咨询等领域。遗憾的是,目前这些大模型的部署依然存在一定的技术门槛,甚至连启动都要通过命令行完成,对于没有相关技术背景的使用者而言,体验简直一塌糊涂。这种时候,像YourChat这样的产品简直就像一缕曙光,让习惯使用图形用户界面的一般人可以在一个“正常”的窗口中与Llama 2对话。
相信伴随着端侧大模型越来越受到关注,未来一定会出现更便利的部署和使用方式,或是像Autodesk、Adobe那样融入到不同的软件当中,让使用者把更多精力放在工作内容上。
未来,当工作站上的大模型在更多专业领域发挥作用时,那些部署在手机上的“瘦身版”大模型,也将真正成为消费级产品的智能中枢,不再是被遗忘的Siri。
本文章选自《AI启示录》杂志,阅读更多杂志内容,请扫描下方二维码