

国产开源之光:DeepSeek-V3划重点
DeepSeek-V3 采用了 671B 参数 MoE 架构,配备约 37B 激活单元,训练使用14.8T Token数据。

通过博弈来训练辩论模型,提高了裁判模型准确性,也为AI自我监督提供了新思路
探讨如何提高人工智能系统在复杂任务中的透明度和可信度方面,纽约大学数据科学中心的研究人员提出了一种创新方法,通过自我博弈、训练语言模型进行辩论,以提高裁判的判断准确性。

现在的AI公司们,已经在把用户当"数据提款机"了。
最近X(也就是以前的推特)和马斯克,就被这玩意,推上了风口浪尖。原因是,X被发现“光明正大”的拿用户的帖子来训练Grok AI。就是马斯克自己搞的那个大模型。

AI算力产业链及竞争格局分析
目前,AIGC产业生态体系的雏形已现,呈现为上中下三层架构:①第一层为上游基础层,也就是由预训练模型为基础搭建的AIGC技术基础设施层。②第二层为中间层,即垂直化、场景化、个性化的模型和应用工具。③第三层为应用层,即面向C端用户的文字、图片、音视频等内容生成服务。

Unsloth微调Llama3-8B,提速44.35%,节省42.58%显存,最少仅需7.75GB显存
我们实测了Unsloth所带来的训练增益,对Llama3-8B进行QLoRA训练,最少仅需7.75GB显存,这意味着我们可以在一张1080Ti上训练Llama3-8B,进一步降低了大模型训练的硬件门槛。开启Unsloth后,Llama3-8B的训练速度可提升44.35%,训练时间可减少30.72%,显存占用可减少42.58%。更详细的测试设置可参考第三节。
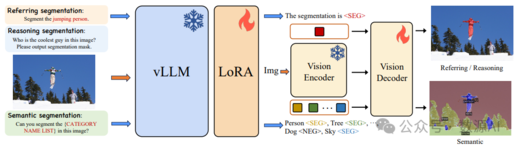
SAM+多模态大模型实现开集分割!清华联合美团提出LaSagnA!
最近进展使大型视觉语言模型 (Large Language Models for Vision,vLLMs) 能够生成详细的感知输出,包 括边界框和掩码。然而,限制这些 vLLMs 进一步应 用的两个约束是:每个查询无法处理多个目标,以及 无法识别图像中查询对象不存在。

省心更要省钱,MIT亲自下场,拒绝“参数内耗”
在人工智能领域,大模型因其在理解和生成自然语言方面的卓越能力而备受关注。通过捕捉和再现人类语言的复杂性和微妙性,为使用者提供了与机器进行自然对话的可能性。
关于弱智吧数据封神的若干疑问和猜想,以及数据验证实验
弱智吧的数据真的这么厉害吗?持着好奇和怀疑的态度,我们仔细阅读了这篇论文,「弱智吧的数据碾压其他数据」这个结论有待深入讨论和探索。我们提出以下几个疑问:
