
MiniGPT4-Video:让大模型分析视频内容,依然有难度
MiniGPT4-Video有待继续调优。
Sora的发布,让文生视频成了过去几个月里最热门的一个话题,与此同时,行业里也涌现出了不少与视频内容分析相关的多模态大模型应用。
MiniGPT4-Video就是最近面世的与视频相关的多模态大模型应用之一。
该应用由KAUST和哈佛大学研究团队在今年4月发表的论文中提出,是一个专为视频理解设计的多模态大模型框架。

这一研究团队在论文中指出,在MiniGPT4-Video出现之前,行业中已经有诸多多模态大模型的研究项目,诸如MiniGPT、Video-ChatGPT等,但这些研究项目各有缺陷,例如Video-ChatGPT在对视频中内容进行转换过程中,往往会造成信息丢失,而且无法充分利用视频中的动态时间信息。
他们提出的MiniGPT4-Video是通过将每四个相邻视觉标记连接,减少了标记数量,同时也降低了信息损失对应用带来的影响。
与此同时,他们通过为视频的每一帧添加字幕,从而将每一帧表示为由视频编码器提取的视觉标记与由LLM标记器提取的文本标记的组合,这让大模型能够更全面地理解视频内容,从而同时响应视觉和文本查询信息。
众所周知,对于多模态大模型而言,数据最为关键。
据悉,为了训练MiniGPT4-Video,该研究团队用到了三个数据集:
第一个数据集是包含了15938个浓缩电影视频字幕的视频作为数据集(CMD),在这个数据集中,每个视频长度为1-2分钟;
第二个数据集是牛津大学发布的一个拥有200万视频量的开源数据集Webvid,为了和CMD数据保持一致,该研究团队将这一数据集中的数据也都裁剪到了1-2分钟;
第三个数据集是一个拥有13224个视频、100000个问答对话和注解的数据集,这个数据集中的数据质量很高,不仅针对视频内容提供了平均57个单词组成的问题答案,这些问题还涵盖多种问题类型,例如视频摘要、基于描述的QA,以及时间、空间、逻辑关系方面的推理。
由此研发出的这样一个MiniGPT4-Video模型,究竟能有什么用?
该研究团队在研究过程中,一共测试了MiniGPT4-Video三项能力:视频ChatGPT能力、开放式问题回答能力、选择题回答能力。
作为通过视频数据训练的多模态,MiniGPT4-Video最核心的能力其实是开放式问题的回答能力。
就这一能力,至顶网分别找了三个视频进行了实际测试——一个是由Pika生成的3秒煎肉视频、一个是42秒的机器人演示视频、一个是50秒的《老友记》节选片段。
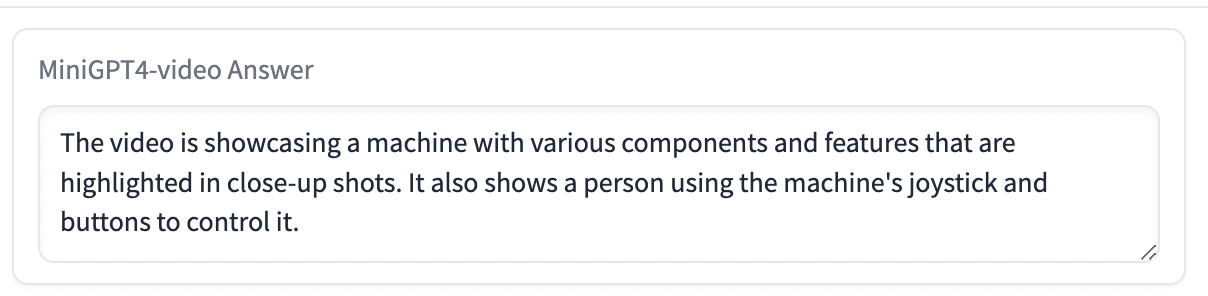
先说测试结果,将三个视频分别上传,并对MiniGPT4-Video进行提问——“这个视频谈了什么?”后,最终只有第二个视频给出了完整的答案,给出的答案与视频内容基本一致。
由此可见,现在的MiniGPT4-Video在做视频内容解析时,不仅对视频长度有要求,对视频质量同样有较高的要求,第二个视频之所以能有不错的输出结果,主要是因为视频内容逻辑性更强,而且有一些字幕介绍。

不过,针对第二个视频,我们就同一问题进行了多次提问,给出的答案并不一致,这是生成式AI的特性,第二次给出的答案还将视频中的机器人识别成了人,整体描述也出现了错误。
现在看来,MiniGPT4-Video在实际使用时,仍会存在各种各样的问题,还有待研究团队继续调优。
本文章选自《数字化转型方略》杂志,阅读更多杂志内容,请扫描下方二维码