


字节Seed团队绝地翻盘,发现多模态模型也有涌现时刻,开源BAGEL模型
北京时间5月21日,百度发布2025年第一季度财报,这场会议不仅仅是一次常规的财务数据披露,更像是百度在AI时代战略布局的全景展示,李彦宏在开场发言中,将2025年第一季度形容为一个“稳健的开局”。

Startup Korl 推出多模态、多代理工具,实现跨系统定制化沟通
Korl 利用 OpenAI、Gemini 及 Anthropic 等模型,从 Salesforce、Jira、Google Docs 等多个平台整合数据,自动生成定制化客户沟通材料,如幻灯片、演讲稿及季度业务回顾,同时保证数据安全性,并提升运营效率。

Exaforce 融资7500万美元以扩展结合多模态 AI 的 agentic SOC 平台
Exaforce 创立于 2023 年,其自主 SOC 平台利用多模态 AI 引擎整合语义、统计及行为模型,实现自动化日志分析与威胁检测,显著降低人工操作,同时提升安全响应效率。

2025人工智能行业趋势报告|大模型之家年度专题
近年来,随着深度学习、自然语言处理、计算机视觉等技术的快速发展,多模态技术取得了显著进展。商汤秒画、Sora、可灵等文生图、文生视频等模型产品的推出,让AI生成的内容更加丰富多彩,极大地丰富了用户体验和应用场景。

人工智能的下一个前沿:多模态系统将重塑我们的世界
想象一下,一个人工智能系统不仅能阅读文本或识别图像,还能够同时读、写、看、听和创造。这其实就是多模态人工智能的精髓。这些先进的多模态人工智能系统可以同时处理和整合多种形式的数据,包括文本、图像、音频甚至视频。这就像是赋予了人工智能一整套的感官。

基于Gemini!Waymo提出端到端自动驾驶多模态模型EMMA!
我们介绍了EMMA,一个端到端的自动驾驶多模态模型。基于多模态大型语言模型的基础,EMMA直接将原始相机传感器数据映射到各种特定于驾驶的输出中,包括规划器轨迹、感知对象和道路图元素。EMMA通过将所有非传感器输入(例如导航指令和自我车辆状态)和输出(例如轨迹和3D位置)表示为自然语言文本,最大化了预训练大型语言模型的世界知识效用。

阿里提出LLaVA-MoD架构!利用MOE技术让小模型也能大显身手!
多模态大型语言模型(MLLM)通过在大型语言模型(LLM)中集成视觉编码器,在多模态任务中取得了有希望的结果。然而,大型模型的大小和广泛的训练数据带来了显著的计算挑战。例如,LLaVA-NeXT的最大版本使用了Qwen-1.5-110B,并且使用128个H800 GPU训练了18小时。

Qwen2-Audio:多模态AI系统,融合语音对话和音频分析功能
多模态AI系统,融合语音对话和音频分析功能,支持超过8种语言和方言,无需自动语音识别即可进行语音交互,提供音频信息分析和多语言支持。

大模型之家2024年7月热力榜:视频生成热潮来袭,多模态赛道再升级
巴黎奥运会上,AI技术的应用成为了赛事的一大亮点。从智能裁判系统到运动员训练辅助,再到赛事直播的个性化推荐,AI技术的融入不仅提升了赛事的公平性和观赏性,也让观众享受到了前所未有的观赛体验。

搞了半天原来GPT-4o-mini是基于GPT-3.5架构的模型(Dify中接入GPT-4o mini模型)
GPT-4o mini("o"代表"omni")是小型型号类别中最先进的型号,也是OpenAI迄今为止最便宜的型号。它是多模态的(接受文本或图像输入并输出文本),具有比 gpt-3.5-turbo 更高的智能,但速度同样快。它旨在用于较小的任务,包括视觉任务。

AI算力产业链及竞争格局分析
目前,AIGC产业生态体系的雏形已现,呈现为上中下三层架构:①第一层为上游基础层,也就是由预训练模型为基础搭建的AIGC技术基础设施层。②第二层为中间层,即垂直化、场景化、个性化的模型和应用工具。③第三层为应用层,即面向C端用户的文字、图片、音视频等内容生成服务。

AGI万字长文(上) | 2023回顾与反思
2023年大众对AI的看法从怀疑到认可,AGI(通用人工智能)的发展迅速,大模型展现出惊人的想象力和取悦能力。应用层尚未出现独角兽,创业者面临官方技术迭代的挑战。

大模型现状和未来:百模征战,产业智能跃迁(2024)
AI大模型通过大规模预训练和微调实现通用人工智能,目前正从'大炼模型'向'炼大模型'转变,推动多模态和多场景革命。GPT模型迭代加速,国内企业如百度、腾讯、阿里在大模型市场占据优势。
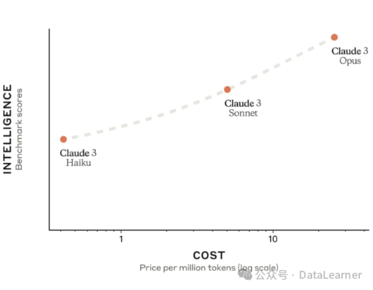
评测结果超过GPT-4,Anthropic发布第三代大语言模型Claude3,具有多模态能力,实际评测表现优秀!但幻觉问题不小!
Anthropic推出了第三代大语言模型Claude3,包含三个版本:Claude3-Opus、Claude3-Sonnet和Claude3-Haiku,能力和成本递减。Claude3-Opus在多项评测中超过GPT-4,支持多模态和最高100万上下文输入。


用双眼见证未来:以人工智能治疗年龄相关性黄斑变性
由于专家不足且高度依赖临床专业知识来评估视网膜成像情况,确定年龄相关性黄斑变性的高风险人群一直是个令人头痛的难题。但如今,人工智能/机器学习(AI/ML)等新兴技术的逐步普及,正为更准确、更高效的筛查方法铺平道路。

AISHU,爱数技术梦想新征程
12月5日,以数据「智」上为主题的多模态数据智能峰会在北京举行,以多模态数据智能为核心战略的爱数AISHU品牌新征程,爱数成功展示了从图像到文本的跨模态场景应用,迈出了从单模态数据分析到多模态数据智能的第一步。

百度王海峰:多模态深度语义理解将让AI更深地理解真实世界
7月4日召开的百度AI开发者大会上,百度高级副总裁、AI技术平台体系(AIG)总负责人王海峰发布百度大脑3.0,并指出,百度大脑3.0的核心是“多模态深度语义理解”,包括数据的语义,知识的语义,以及图像、视频、声音、语音等各方面的理解。
