
检索增强生成 关键字列表

体验完百度世界2024上的iRAG,我觉得AI绘图也可以没有幻觉了。
本质上,他是不是大模型按照自己的知识库回答,然后先通过一些工程化手段,比如联网搜索,比如文档搜索等等,先把相关信息给找出来,让大模型根据这些信息来进行回答。

一文读懂 Agentic RAG 数据检索范式
通常而言,RAG 赋予了语言模型获取和处理外部信息的能力,使其不再被限制在固有的知识范畴内。通过将语言模型与信息检索系统结合,RAG 允许模型动态地从互联网、知识库或其他外部来源检索相关内容,并将这些内容融合到生成的响应中。这一机制确保了生成的答复不仅贴近真实世界,内容更加翔实可信,从而显著提升了语言模型在处理复杂问题时的表现。

2024-05-13
Fine-Tuning Vs RAG ,该如何选择?
随着技术的不断进步,LLM 带来了前所未有的机遇,吸引了开发者和组织纷纷尝试利用其强大的能力构建应用程序。然而,当预训练的 LLM 在实际应用中无法达到预期的性能水平时,人们将不由自主地开始思考:我们到底应该使用哪种技术来改善这些模型在特定场景下的表现?
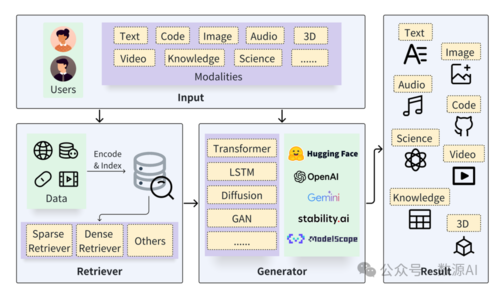
最新RAG综述来了!北京大学发布AIGC的检索增强技术综述
北京大学崔斌教授领导的数据与智能实验室发布了关于检索增强生成(RAG)技术的综述,涵盖近300篇相关论文。RAG技术结合检索与生成,用于问答、对话生成等AI任务,展现出卓越潜力。

白皮书