
数据集 关键字列表

企业AI:如何构建AI数据集
首先考虑企业已经拥有的、或者可以使用的、符合要求的数据和数据集。接下来,你需要决策点透明度,以及信号值来评估可用性、可行性和业务效果等因素,或者潜在表现与竞争对手相比的数据等。

微软用AI Agent生成2500万对高质量数据,极大提升大模型性能!
为了解决训练数据短缺和质量差的难题,微软研究院发布了一个专门用于生成高质量合成数据的的AI Agent——Agent Instruct。

2024-09-02
商汤、清华、复旦等开源百亿级多模态数据集,可训练类GPT-4o模型
商汤科技等机构联合开源了百亿级图文交错数据集OmniCorpus,规模是现有数据集的15倍,包含86亿张图像和16,960亿个文本标记。OmniCorpus数据集在多语言、多类型数据抓取上进行了优化,提高了内容提取的质量和完整性。通过人工反馈和自动过滤规则,确保了数据集的高质量。在VQA和Image Captioning等测试中,基于OmniCorpus预训练的模型表现出色,对训练多模态大模型有重要帮助。
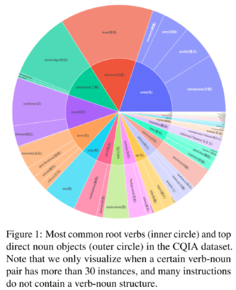
关于弱智吧数据封神的若干疑问和猜想,以及数据验证实验
弱智吧的数据真的这么厉害吗?持着好奇和怀疑的态度,我们仔细阅读了这篇论文,「弱智吧的数据碾压其他数据」这个结论有待深入讨论和探索。我们提出以下几个疑问:
“弱智贴吧”的数据,居然是最强中文语料库
在大模型领域英语一直是训练数据最重要的语言,但由于中英文的结构和文化差异,直接将英文数据集翻译成中文并不理想。所以,为了填补高质量中文数据集的空白,研究人员开发出了COIG-CQIA数据集。

投入3700多万美元,澳大利亚推出了维多利亚州的数字孪生
澳大利亚维多利亚州日前宣布正式推出维多利亚州数字孪生(DTV)平台,旨在提供相关数据的可视化、探索和规划。

白皮书