

NVIDIA GPUs H100 vs A100,该如何选?
在人工智能和高性能计算领域,GPU 扮演着至关重要的角色。作为 GPU 领域的领导者,NVIDIA 推出的 H100 和 A100 两款产品备受瞩目。H100 作为 A100 的继任者,在架构、性能和功能上都进行了显著的提升。本文将深入剖析这两款 GPU 的技术细节、性能差异以及应用场景,帮助读者全面了解 H100 和 A100,从而在实际应用中做出明智的选择。

该需要多少 NVIDIA CUDA Cores ?
在 GPU 众多特性中,NVIDIA GPU 凭借其独特的 CUDA 架构和丰富的 CUDA 核心而备受瞩目。然而,由于 GPU 资源的高昂成本和相对稀缺性,如何根据实际需求选择合适的 GPU 变得尤为重要。

Dynamic GPU Fractions(动态 GPU 分配),知多少?
随着人工智能和高性能计算需求的爆炸式增长,图形处理器(GPU)已成为支撑复杂计算任务的关键基础设施。然而,传统的 GPU 资源分配方式通常采用静态分配模式,即在任务启动时预先分配固定的 GPU 资源。这种静态分配方式往往导致资源利用率低下,尤其是在工作负载波动较大或资源需求不确定的场景中,造成宝贵的计算资源闲置浪费。

深度学习最佳 GPU,知多少?
在深度学习领域,GPU因其并行计算能力成为理想硬件解决方案。GPU处理大规模数据集时高效,尤其适合AI中的矩阵运算。NVIDIA A100、RTX 4090、Quadro RTX 8000和AMD Radeon VII是深度学习的推荐GPU型号,各有特点和适用场景。选择GPU时需考虑CUDA核心、Tensor核心、显存容量、框架兼容性及预算。

一文读懂 NVIDIA GPU 产品线
然而,NVIDIA GPU 的命名规则较为复杂,涉及架构代号(如 Ampere、Hopper)、性能等级(如 A100、A40)以及其他技术特征等多重维度,这使得用户在选择时容易感到困惑。要充分理解这些不同显卡的性能特征、成本效益,乃至仅仅记住它们繁复的命名规则,对许多用户来说都是一项不小的挑战。

一文读懂如何基于 Traefik AI 网关构建高性能微服务架构
Traefik,作为一款云原生环境下流行的反向代理和负载均衡器,以其动态配置、智能路由和卓越性能,为构建高性能 AI 网关提供了强大的支持。

一文读懂 GPU 资源动态调度
众所周知,随着人工智能、深度学习以及高性能计算(HPC)的快速发展,GPU (Graphics Processing Unit)已经成为现代计算体系中的核心计算资源之一。相比传统的 CPU,GPU 在并行计算方面具备显著优势,加速大规模数据处理和复杂计算的关键。

一文读懂 Chatbots(聊天机器人)是如何提高营销投资回报率?
通常而言,聊天机器人通过整合自然语言处理(NLP)、机器学习(ML)和语音识别等技术,使其能够准确解析用户输入、理解意图并生成适当的响应。这种交互方式极大地提高了人机沟通的效率和友好度。与传统交互形式相比,聊天机器人以自然语言为桥梁,使用户无需具备技术背景也能轻松使用复杂系统。

LangGraph,知多少?
LangGraph是LangChain生态系统的新框架,专为构建基于大语言模型的有状态、多代理应用程序而设计。它支持循环流程,提供精细的控制能力,具备持久性特性,并能与人类协作。LangGraph适用于个人助理、AI教师、软件用户体验优化、空间计算和构建智能操作系统等多种场景。

CUDA vs OpenCL:GPU 编程模型该如何选?
近年来,GPU(图形处理单元)已从最初的图形渲染专用硬件,发展成为高性能计算领域的“加速器”,为各类计算密集型任务提供了强大的并行计算能力。GPU 编程,即利用 GPU 的并行架构来加速应用程序的执行,已成为推动科学计算、人工智能、大数据等领域快速发展的重要驱动力。

CPU vs. GPU vs. TPU,该如何选择 ?
人工智能(AI)和机器学习(ML)技术的飞速发展,正深刻地改变着我们的生活和工作方式。为了满足日益复杂的 AI 应用对计算能力的迫切需求,半导体行业正经历着一场前所未有的变革。传统的 CPU 虽然在通用计算方面表现出色,但在面对大规模并行计算任务时,其性能瓶颈日益凸显。

CPU vs GPU:为什么GPU更适合深度学习?
凭借其卓越的数据处理能力,深度学习使得计算机能够实现多种过去仅为人类所独有的认知智能。通常而言,深度神经网络的训练过程极其复杂,通常需要进行大量的并行计算。

AutoGen:赋能大模型,解锁无限可能
在实际业务场景中,赋予语言模型更强大能力的主要方式有两种:一种是通过特殊管道向模型输送额外信息,另一种是让模型自主使用各种工具。

关于 GPU ,你所应该了解的
Luga讨论了GPU在人工智能生态中的重要性,特别是在加速AI核心算力构建方面。GPU以其高度并行的架构,在深度学习等AI技术中展现出卓越性能。与CPU相比,GPU在处理图形渲染、机器学习、视频编辑等计算密集型任务时具有显著优势。GPU和CPU的协同工作提高了数据吞吐量和并发计算能力。GPU的应用场景包括专业可视化、机器学习、区块链和模拟技术等领域。

一文读懂 Agentic RAG 数据检索范式
通常而言,RAG 赋予了语言模型获取和处理外部信息的能力,使其不再被限制在固有的知识范畴内。通过将语言模型与信息检索系统结合,RAG 允许模型动态地从互联网、知识库或其他外部来源检索相关内容,并将这些内容融合到生成的响应中。这一机制确保了生成的答复不仅贴近真实世界,内容更加翔实可信,从而显著提升了语言模型在处理复杂问题时的表现。

Multi-Agent ,知多少?
AI Agent 已经成为生成人工智能应用程序的重要组成部分。然而,为了能够有效地与复杂环境进行互动,这些代理需要具备强大的推理能力,以便能够独立做出决策并帮助用户解决各种任务。行为和推理之间存在着紧密的协同联系,这对于 AI Agent 快速学习新任务非常有帮助。

LLM (大模型)评估框架知多少?
随着 LLM 的快速发展和改进,我们正在面对新的挑战和机遇。LLM 的能力和表现水平不断提高,这使得基于单词出现的评估方法(如 BLEU)可能无法完全捕捉到 LLM 生成文本的质量和语义准确性。LLM 能够生成更加流畅、连贯且语义丰富的文本,而传统的基于单词出现的评估方法则无法准确衡量这些方面的优势。

一文读懂 GPT-4o vs GPT-4 Turbo
OpenAI 创新性地推出了其最先进、最前沿的模型 GPT-4o,这是标志着人工智能聊天机器人和大型语言模型领域实现重大飞跃的突破性举措。预示着人工智能能力的新时代 ,GPT-4o 拥有显着的性能增强,在速度和多功能性方面都超越了其前身 GPT-4。

Fine-Tuning Vs RAG ,该如何选择?
随着技术的不断进步,LLM 带来了前所未有的机遇,吸引了开发者和组织纷纷尝试利用其强大的能力构建应用程序。然而,当预训练的 LLM 在实际应用中无法达到预期的性能水平时,人们将不由自主地开始思考:我们到底应该使用哪种技术来改善这些模型在特定场景下的表现?
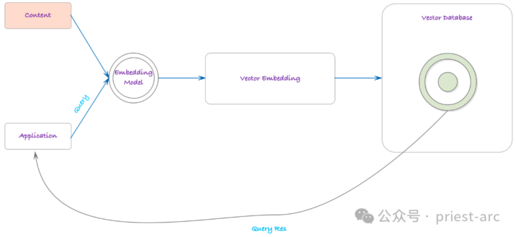
一文读懂 LLM 的构建模块:向量、令牌和嵌入
本文讨论了构建大型语言模型(LLM)的关键要素:向量、令牌和嵌入。向量是机器理解语言的基础,通过将文本数据转换为高维向量空间中的表示。令牌是文本数据在模型内部的表示形式,可以是单词、子词或字符。嵌入则是融入了语义语境的令牌表征,代表文本的意义和上下文信息。这些组件共同构筑了LLM的技术支柱,赋予模型卓越的语言理解和生成能力。

