


AMD这一把算是把AI玩明白了
自2017年AMD回归数据中心处理器,到去年已经提供了第四代AMD EPYC(霄龙)处理器,帮助云、企业和高性能计算等关键应用负载。今年,AMD首席执行官苏姿丰(Lisa Su)也没有让我们失望,抢先带来了包括CPU和GPU在内的一系列更新。

英特尔宣布放弃CPU-GPU引擎,转而将NNP引入GPU
最近于汉堡举行的ISC23超级计算大会上,英特尔再次阐明了对于Falcon Shores的规划,确认该设备就是纯GPU计算引擎,而且目前发布混合XPU的时机还不成熟。

英特尔称AI已主导CPU、GPU乃至云设施,因此Meteor Lakes将全系配备VPU
Movidius技术已在第13代酷睿芯片中有所应用,并将成为下一代消费级芯片的主流配置。
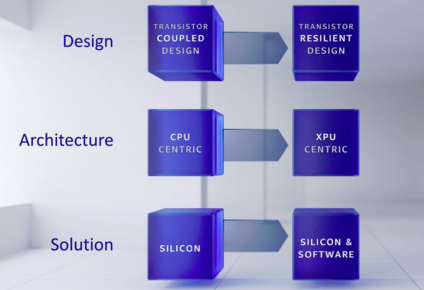
英特尔放弃将CPU、GPU与内存纳入同一封装的XPU开发计划
英特尔曾发下宏愿,立场将CPU、GPU和内存芯片塞进统一的XPU封装当中。但如今,这个目标已然宣告失败。

英伟达GPU的生命循环——产自晶圆厂,又用于晶圆厂
台积电、ASML和Synopsys都在使用英伟达加速器来加速或支持计算光刻技术。与此同时,KLA Group、Applied Materials和日立也在英伟达的并行处理芯片上运行深度学习代码,借此进行电子束与光学晶圆检测。

把握历史性时刻,谷歌决意投资GPU计算
在一年前的谷歌I/O 2022大会上,谷歌向全世界展示了其内部机器学习中心使用的8-pod TPUv4加速器,包含总计32768个第四代原研矩阵数学加速器。


窥见未来:英伟达AI推理的前进之路
在英伟达,负责引导研究朝着应用、而非纯学术项目前进的,是斯坦福大学计算机科学与电气工程兼职教授,公司首席科学家、高级研究副总裁以及GPU、网络与CPU芯片设计师Bill Dally。
分析:Nvidia在公有云中保持强劲的增长势头
Nvidia的GPU是业内最常见、最强大的。除了硬件之外,NVIDIA还通过软件工具推进Nvidia的普及,这些软件工具涵盖了从边缘推理到自动驾驶再到医学成像的各个领域,潜力无限。

微软发布最新AI优化的Azure实例
微软公司Azure高性能计算和人工智能群组首席项目经理Matt Vegas在博客文章中写道:“为我们的客户兑现高级人工智能的承诺,这需要超级计算基础设施、服务和专业知识,以应对呈指数级增长的规模和最新模型的复杂性。

摩尔线程为“完美体验”持续进化 加速云桌面产品生态共建
GPU创业是一个长期事业,充满了挑战,我们深知生态的重要性。我们只有与生态伙伴、行业用户凝聚在一起,才能将摩尔线程的算力真正发挥出来。

加速视频解码与转码性能 中科大洋展示英特尔数据中心GPU Flex 140创新应用成果
在近日举行的“应云而变,携手加速创新”为主题的英特尔数据中心GPU Flex系列媒体沟通会上,中科大洋技术研究院院长褚震宇分享了英特尔GPU在视频解码与转码方面的创新实践。

领先技术与广泛生态 英特尔Flex系列GPU为市场带来更多选择
英特尔基于XPU战略打造了跨CPU、GPU、FPGA、IPU等多种架构的算力资源支持未来的应用。其中,最新的英特尔Flex系列GPU采用了突破性设计,可以应对算力挑战、满足新兴智能视觉云负载所需的多项软硬件创新及突出的灵活性和可扩展性。
英特尔重磅发布Max系列CPU和GPU 剑指高性能计算和人工智能市场
英特尔近日发布了最新产品Intel Max系列,希望以此在高性能计算和人工智能市场与竞争对手AMD及Nvidia展开竞争。

有意见 | 为替代被管制的A100,英伟达为中国特制了“低配版”
近日,英伟达宣布将在中国推出一款全新A800芯片,作为A100芯片的替代,两者都是图形处理器芯片。

“春晓”初成,国潮现世,摩尔线程绘出一幅GPU创“芯”图
摩尔线程在北京发布多款软硬件新品,包括新一代GPU“春晓”、面向个人电脑的消费级显卡MTT S80和服务器计算卡MTT S3000、一体化计算设备“MCCX元计算一体机”,以及开发套件、数字人解决方案等。
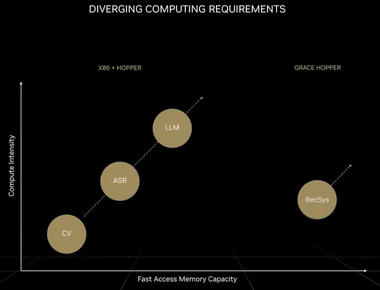
系统设计的艺术:当HPC与AI应用成为主流,GPU架构该向何处去?
如今的超级计算机尽管无比强大,但仍不足以预测未来。至于超级计算机自身的未来,那就更加难以预料。

捉对厮杀:一场数据中心GPU竞赛
虽然英特尔早已是GPU市场上的老玩家,甚至很难在过去几十年来找到比英特尔更热衷于整合GPU业务的厂商,但芯片巨头的这条探索之路仍然走得步履蹒跚。
